Options Reference
This page documents every option you can pass in the options dictionary of your DAG configuration. Options are organized by scope: common options apply to all orchestrators, while backend-specific options only apply to a given orchestrator or execution environment.
All options are string values in YAML:
dag:
options:
option_name: "value"
Common options
These options are recognized by all orchestrators and execution environments.
sl_env_var
Starlake environment variables passed as a JSON-encoded string. These variables are injected into the execution environment of every task.
| Type | JSON string |
| Default | {} |
| Required | No |
dag:
options:
sl_env_var: '{"SL_ROOT": "/opt/starlake", "SL_DATASETS": "/opt/starlake/datasets", "SL_ENV": "PROD", "SL_TIMEZONE": "Europe/Paris"}'
Common variables inside sl_env_var:
| Variable | Description |
|---|---|
SL_ROOT | Root directory of the Starlake project |
SL_DATASETS | Datasets directory (defaults to ${SL_ROOT}/datasets) |
SL_ENV | Environment name (e.g., SNOWFLAKE, BIGQUERY, SPARK) |
SL_TIMEZONE | Timezone for scheduling |
SL_LOG_LEVEL | Logging level |
pre_load_strategy
Defines the strategy used to conditionally load the tables of a domain.
| Type | none | imported | ack | pending |
| Default | none |
| Required | No |
dag:
options:
pre_load_strategy: "imported"
NONE
No pre-load check. The domain loads unconditionally.
- Airflow
- Dagster
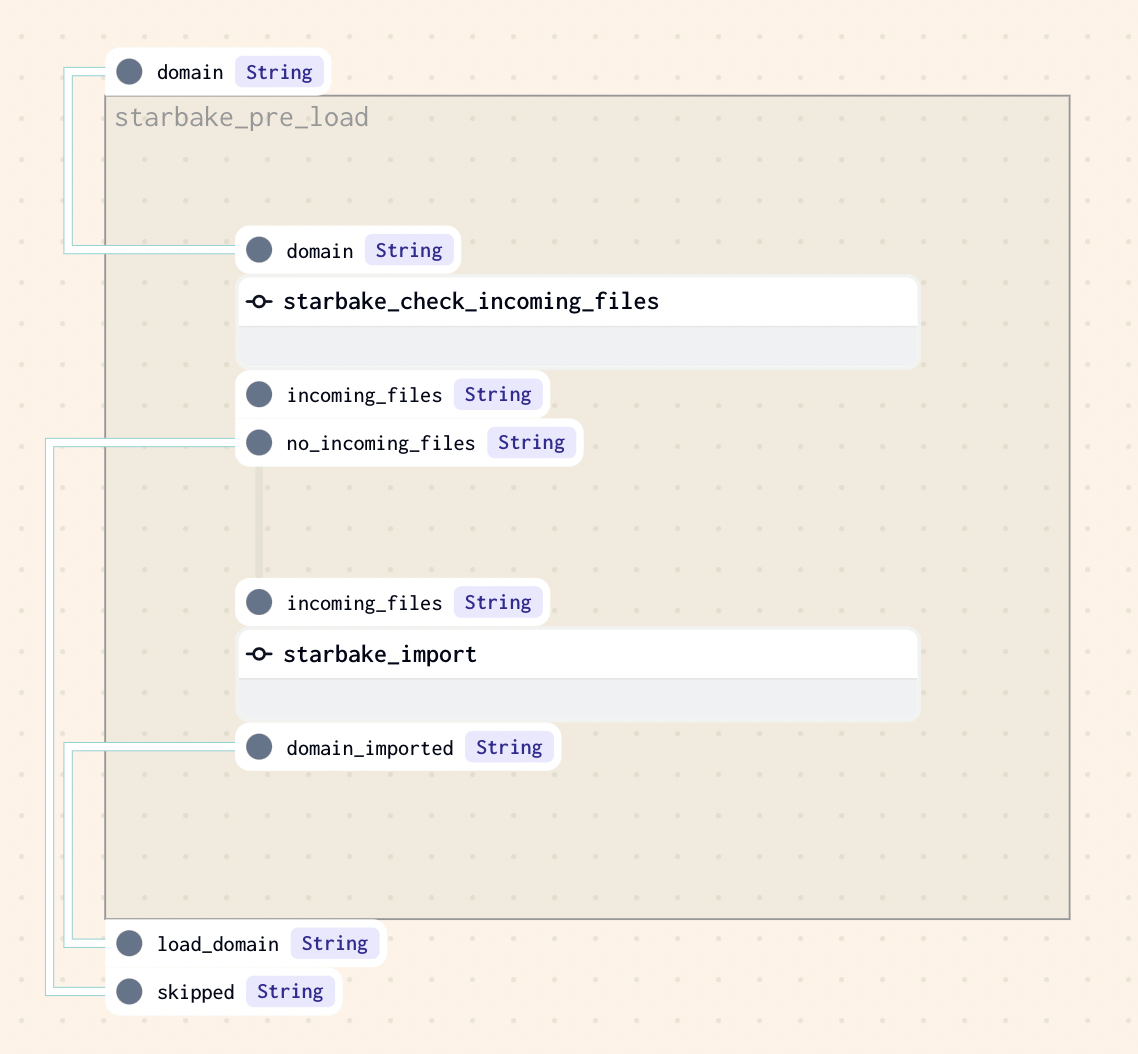
IMPORTED
Checks that at least one file exists in the landing area (${SL_ROOT}/incoming/{domain} by default). If files are found, sl_import is called to import the domain before loading. Otherwise, loading is skipped silently.
pre_load_strategy: "imported"
- Airflow
- Dagster

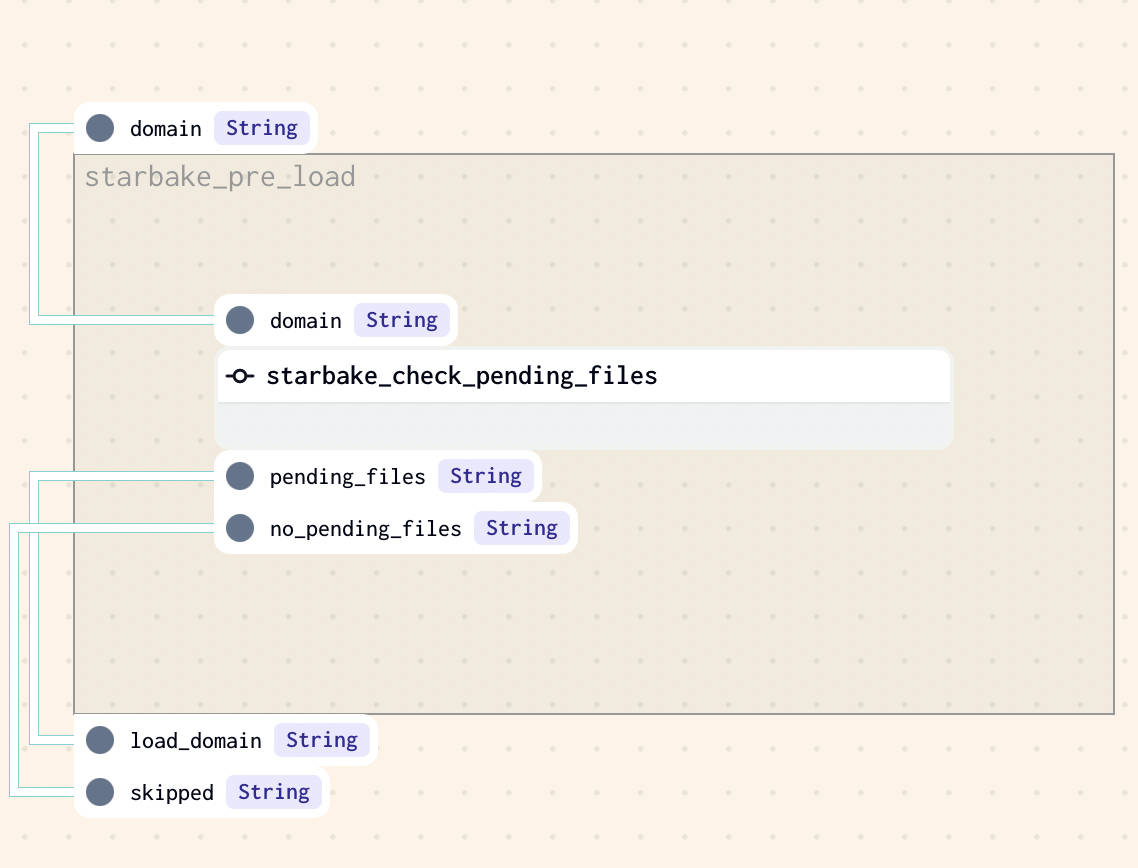
PENDING
Checks that at least one file exists in the pending datasets area (${SL_ROOT}/datasets/pending/{domain} by default). Otherwise, loading is skipped.
pre_load_strategy: "pending"
- Airflow
- Dagster

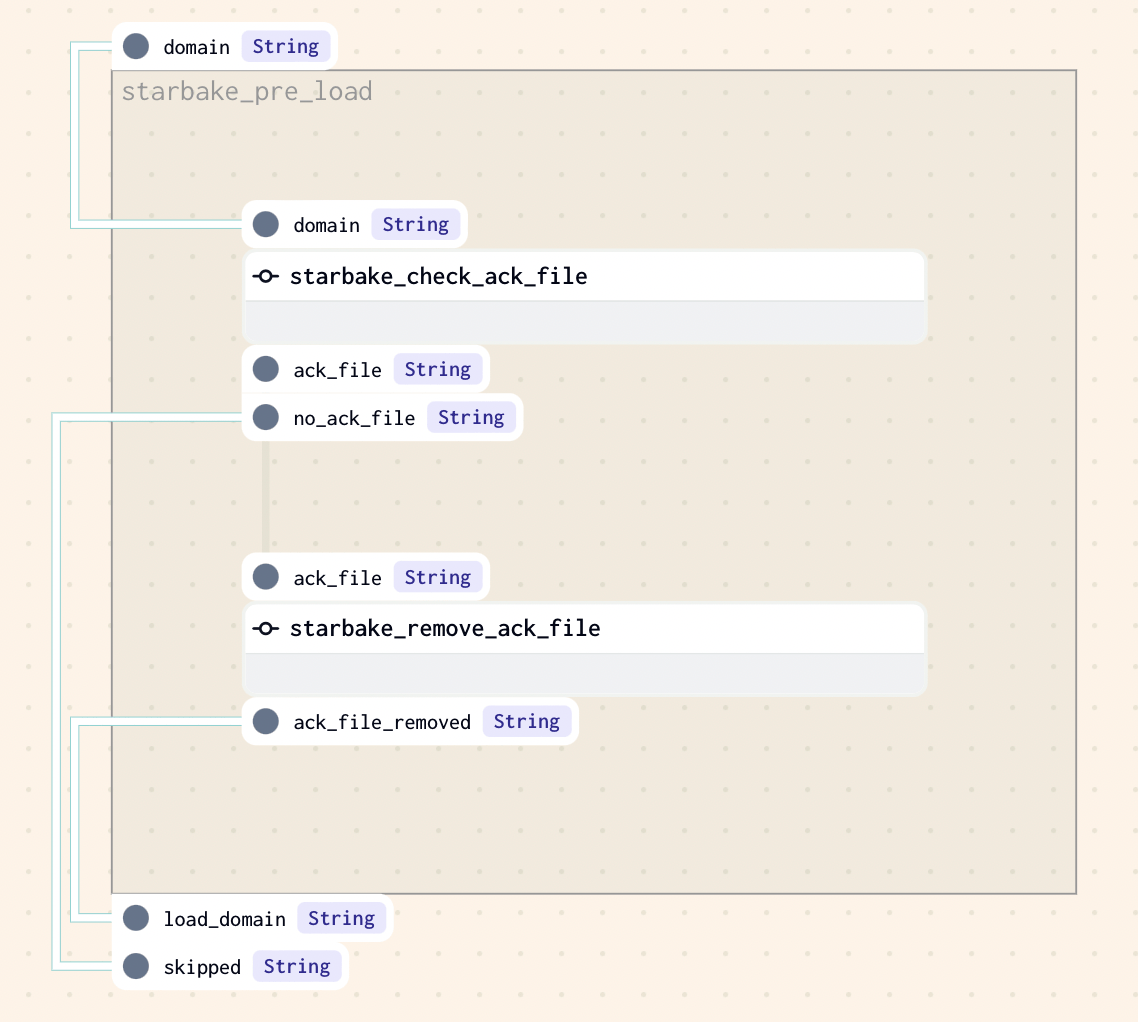
ACK
Checks that an acknowledgment file exists at the specified path (${SL_ROOT}/datasets/pending/{domain}/{date}.ack by default). Otherwise, loading is skipped.
pre_load_strategy: "ack"
Related options for ACK strategy:
| Option | Default | Description |
|---|---|---|
global_ack_file_path | ${SL_DATASETS}/pending/{domain}/{date}.ack | Path to the acknowledgment file |
ack_wait_timeout | 3600 (1 hour) | Timeout in seconds to wait for the ACK file |
- Airflow
- Dagster

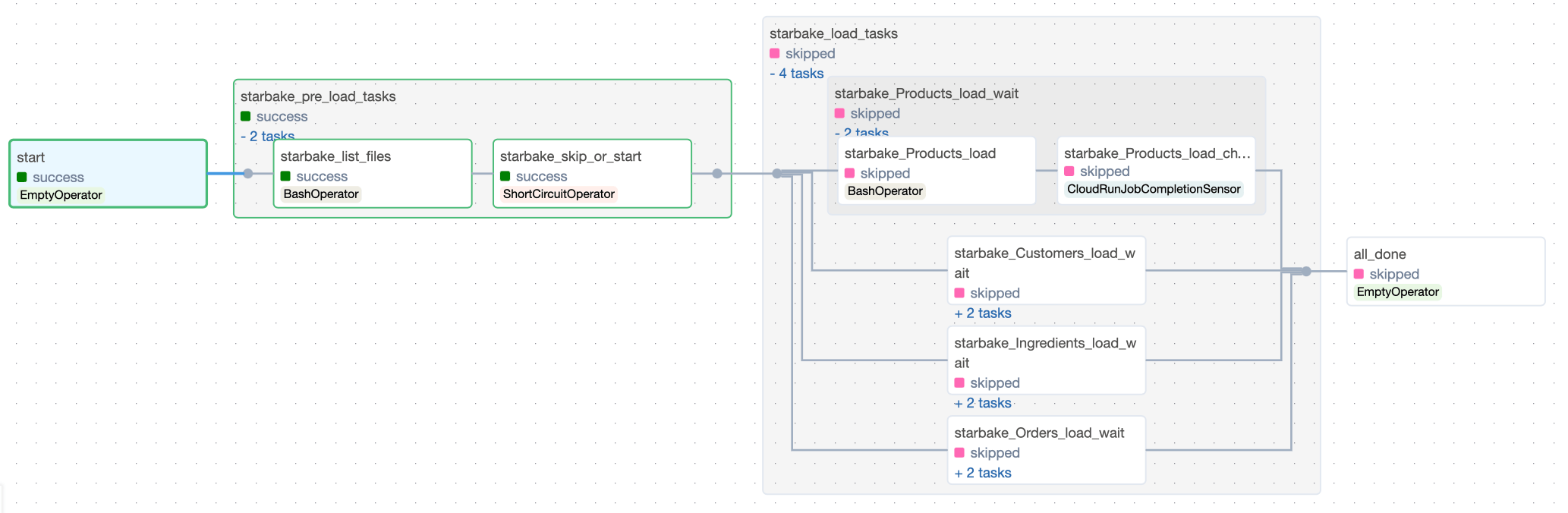
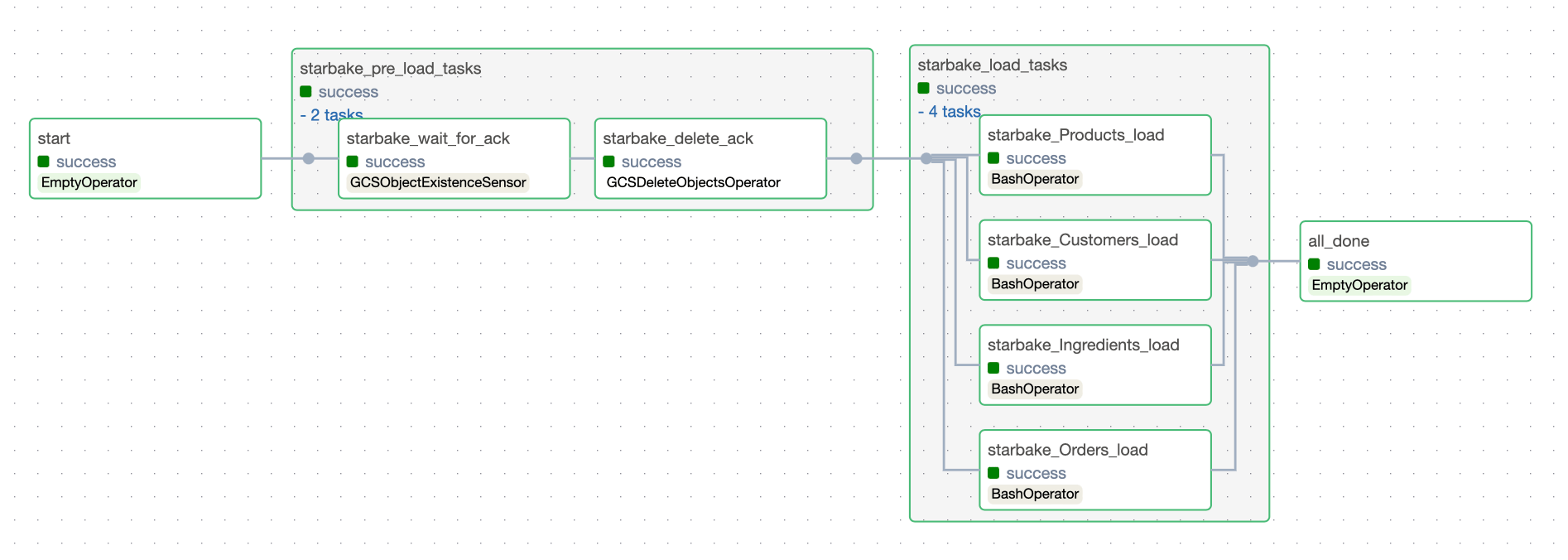
pre_load_not_ready_sentinel_path
Opt-in feature that disambiguates "files not ready yet" from "real error" when the pre-load step runs inside a Cloud Run job.
Applies to: StarlakeAirflowCloudRunJob, StarlakeDagsterCloudRunJob (GCP Cloud Run runner only). Other runners fall through to the legacy behavior.
| Type | string (GCS URI prefix) |
| Default | (unset — feature off) |
| Required | No |
The problem it solves
When a Cloud Run pre-load job exits with code 1, that same exit code is produced by two very different outcomes:
- "Not ready" — files haven't arrived yet (IMPORTED/PENDING find zero files, ACK file missing). The DAG should wait and retry.
- Real error — the pre-load crashed, config is invalid, permissions denied. The DAG should fail fast.
Without this option, the Cloud Run console shows red "Failed" executions for every routine "not ready" poll, and neither Airflow nor Dagster can distinguish the two cases.
How it works
When set, the orchestration layer:
- Appends
--notReadySentinel <resolved-path>to the Cloud Run container arguments. The Starlake CLI writes a zero-byte marker at that path only when the pre-load decides files are not yet ready, and exits0. Genuine crashes still exit non-zero and never write the sentinel. - After the Cloud Run task succeeds, the Airflow
CloudRunJobCompletionSensor(or the Dagster Cloud Run op) checks GCS for the sentinel. If present, it deletes the sentinel and raises an exception so the orchestrator's task-retry machinery re-fires the whole TaskGroup afterretry_delay_in_seconds— that's how "wait for files" is expressed. - If the sentinel is absent, the sensor/op passes and downstream load tasks run.
You gain:
- Clean Cloud Run console. Only genuine crashes show red; "not ready" polls all show green executions.
- Unambiguous "real error" signal. Any non-zero Cloud Run exit now unambiguously means a crash / config error.
- Cross-runner contract. Airflow and Dagster consume the same sentinel via one DagInfo option.
Path contract
The user supplies only a parent prefix. Orchestration automatically appends <domain>/<run_id>.notready, producing concrete paths like gs://my-bucket/_sl/preload/sales/scheduled__2026-04-22T06-00-00.notready. Domain scoping and per-run uniqueness are non-negotiable — these prevent two common footguns (cross-domain collisions, concurrent-run collisions). The run id is resolved by Airflow Jinja on the Airflow side and by an explicit OpExecutionContext.run_id substitution on the Dagster side.
Example
dag:
options:
# Point at a parent prefix — <domain>/<run_id>.notready is appended automatically.
pre_load_not_ready_sentinel_path: "gs://my-bucket/_sl/preload"
# Tune the "wait for files" window. Defaults (retries=0, no retries) mean
# the task fails immediately on the first "not ready" signal — set retries > 0.
# On Cloud Run, retry_delay is overridden per-task by retry_delay_in_seconds.
retries: "12"
retry_delay_in_seconds: "300" # 12 retries × 5 min = ~1h polling window
Recommended hygiene
- Add a GCS lifecycle rule on the
_sl/preload/prefix (e.g., delete after 7 days) as a safety net for orphan sentinels — the sensor normally deletes on detection, but a failed orchestrator restart could leave one behind. - The Starlake CLI version running inside your Cloud Run container must support
--notReadySentinel(introduced alongside this feature). Earlier CLI versions will reject the unknown flag.
run_dependencies_first
When set to true, all dependencies (upstream tables and tasks) for each transformation are generated as tasks within the same DAG. When false (the default), the orchestrator's native data-aware scheduling mechanism is used instead.
| Type | true | false (string) |
| Default | false |
| Required | No |
dag:
options:
run_dependencies_first: "true"
See the Dependencies section for a detailed explanation of both strategies.
retries
Number of times to retry a failed task.
| Type | integer (as string) |
| Default | 0 |
| Required | No |
0 means a failed task fails the DAG immediately — no implicit retries. Set explicitly when you want retry behavior (e.g., when using pre_load_not_ready_sentinel_path, you must set retries > 0 to provide a "wait for files" window).
retry_delay
Delay in seconds between retries.
| Type | integer (as string) |
| Default | 300 |
| Required | No |
For the GCP Cloud Run runner, per-task retry_delay is overridden by retry_delay_in_seconds (default 10s) — so setting retry_delay at the general level has no effect on Cloud Run tasks. Tune retry_delay_in_seconds instead.
start_date
The start date for DAG scheduling, in YYYY-MM-DD format.
| Type | date string |
| Default | File modification date of the DAG |
| Required | No |
timezone
Timezone used for scheduling.
| Type | string |
| Default | UTC |
| Required | No |
tags
Tags applied to the generated DAG, visible in the orchestrator's UI.
| Type | string (space-separated) |
| Default | (none) |
| Required | No |
dag:
options:
tags: "starlake production finance"
cron_period_frequency
The frequency granularity for cron-based scheduling.
| Type | day | week | month | year |
| Default | week |
| Required | No |
dataset_triggering_strategy
Controls how dataset dependencies trigger a DAG run when using data-aware scheduling (run_dependencies_first: "false").
| Type | any | all | custom boolean expression |
| Default | any |
| Required | No |
any— Any single upstream dataset update triggers the DAGall— All upstream datasets must be updated before the DAG triggers- Custom expression — A boolean expression combining dataset names with
&(AND) and|(OR), e.g.dataset1 & (dataset2 | dataset3)
optional_dataset_enabled
Whether datasets can be optional in dependency resolution.
| Type | true | false |
| Default | false |
| Required | No |
data_cycle_enabled
Enables data cycle management for verifying data dependencies.
| Type | true | false |
| Default | false |
| Required | No |
data_cycle
The data cycle frequency. Only used when data_cycle_enabled is true.
| Type | hourly | daily | weekly | monthly | yearly | cron expression |
| Default | none |
| Required | No (only relevant when data_cycle_enabled is true) |
beyond_data_cycle_enabled
Whether to allow runs beyond the data cycle window.
| Type | true | false |
| Default | true |
| Required | No |
min_timedelta_between_runs
Minimum time in seconds between two consecutive DAG runs.
| Type | integer (as string) |
| Default | 900 (15 minutes) |
| Required | No |
Airflow options
These options only apply when using Airflow as the orchestrator.
default_pool
The Airflow pool to use for all tasks in the DAG.
| Type | string |
| Default | default_pool |
| Required | No |
dag:
options:
default_pool: "starlake_pool"
max_active_runs
Maximum number of concurrent active DAG runs.
| Type | integer (as string) |
| Default | 3 |
| Required | No |
end_date
The end date for DAG scheduling, in YYYY-MM-DD format.
| Type | date string |
| Default | (none — runs indefinitely) |
| Required | No |
default_dag_args
Overrides for the default Airflow DAG arguments, as a JSON-encoded string.
| Type | JSON string |
| Default | {"depends_on_past": false, "email_on_failure": false, "email_on_retry": false, "retries": 0, "retry_delay": 300} |
| Required | No |
dag:
options:
default_dag_args: '{"depends_on_past": true, "email_on_failure": true}'
Execution environment options
Each orchestrator supports different execution environments. The execution environment is determined by the template you choose. The following sections document the options specific to each execution environment.
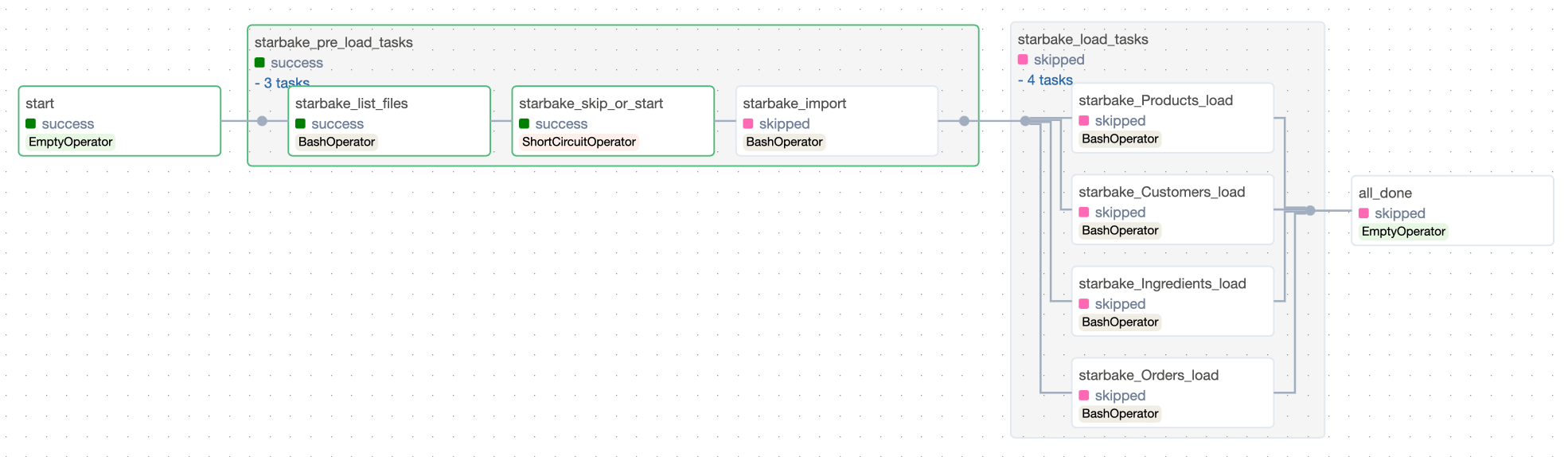
Shell / Bash
Used for on-premise execution of the starlake CLI command directly.
Applies to: StarlakeAirflowBashJob, StarlakeDagsterShellJob
| Option | Default | Required | Description |
|---|---|---|---|
SL_STARLAKE_PATH | starlake | No | Path to the starlake executable |
sl_include_env_vars | GOOGLE_APPLICATION_CREDENTIALS,AWS_KEY_ID,AWS_SECRET_KEY | No | Comma-separated list of OS environment variables to forward to the bash command. Use * or _ to forward all. |
dag:
template: "load/airflow_scheduled_table_bash.py.j2"
options:
SL_STARLAKE_PATH: "/usr/local/bin/starlake"
sl_include_env_vars: "GOOGLE_APPLICATION_CREDENTIALS,AWS_KEY_ID,AWS_SECRET_KEY"
GCP Cloud Run
Executes starlake commands by running a Cloud Run job.
Applies to: StarlakeAirflowCloudRunJob, StarlakeDagsterCloudRunJob
| Option | Default | Required | Description |
|---|---|---|---|
cloud_run_project_id | $GCP_PROJECT env var | No | GCP project ID |
cloud_run_job_name | (none) | Yes | Name of the Cloud Run job to execute |
cloud_run_job_region | $GCP_REGION env var | No | Region where the Cloud Run job is deployed |
cloud_run_service_account | "" | No | Service account for the Cloud Run job |
cloud_run_async | true | No | Run the job asynchronously (Airflow only) |
cloud_run_async_poke_interval | 10 | No | Polling interval in seconds when async (Airflow only) |
retry_on_failure | false | No | (Legacy; no longer consulted by the sensor after the execution-failure fix.) |
retry_delay_in_seconds | 10 | No | Per-task delay in seconds between Airflow retries for this Cloud Run task. Overrides the general retry_delay option for Cloud Run tasks. |
pre_load_not_ready_sentinel_path | (unset) | No | Opt-in sentinel for pre-load "not ready" signaling. See the dedicated section. |
dag:
template: "load/airflow_scheduled_table_cloud_run.py.j2"
options:
cloud_run_project_id: "my-project"
cloud_run_job_name: "starlake-transform"
cloud_run_job_region: "europe-west1"
cloud_run_async: "true"
When asynchronous execution is enabled (default), a completion sensor polls for job completion:
When synchronous:
GCP Dataproc
Submits starlake commands as Spark jobs on a Dataproc cluster.
Applies to: StarlakeAirflowDataprocJob, StarlakeDagsterDataprocJob
Cluster options
| Option | Default | Required | Description |
|---|---|---|---|
cluster_config_name | DAG filename (lowercased) | No | Cluster configuration name identifier |
dataproc_project_id | $GCP_PROJECT env var | No | GCP project ID |
dataproc_region | europe-west1 | No | GCP region for the Dataproc cluster |
dataproc_subnet | default | No | VPC subnet for the cluster |
dataproc_service_account | Auto-generated from project ID | No | Service account for the cluster |
dataproc_image_version | 2.2-debian12 | No | Dataproc image version |
dataproc_name | dataproc-cluster | No | Name of the Dataproc cluster |
dataproc_idle_delete_ttl | 3600 | No | TTL in seconds before idle cluster is deleted |
dataproc_cluster_metadata | {} | No | Cluster metadata as JSON |
Master node options
| Option | Default | Description |
|---|---|---|
dataproc_master_machine_type | n1-standard-4 | Machine type for the master node |
dataproc_master_disk_type | pd-standard | Disk type for the master node |
dataproc_master_disk_size | 1024 | Disk size in GB for the master node |
Worker node options
| Option | Default | Description |
|---|---|---|
dataproc_num_workers | 4 | Number of worker instances |
dataproc_worker_machine_type | n1-standard-4 | Machine type for worker nodes |
dataproc_worker_disk_type | pd-standard | Disk type for worker nodes |
dataproc_worker_disk_size | 1024 | Disk size in GB for worker nodes |
Spark options
| Option | Default | Description |
|---|---|---|
spark_jar_list | (none) | Comma-separated list of JAR files to include |
spark_job_main_class | ai.starlake.job.Main | Main class for the Spark job |
spark_bucket | (none) | GCS bucket for Spark event logs and temporary storage |
spark_executor_memory | (none) | Spark executor memory (e.g., 11g) |
spark_executor_cores | (none) | Spark executor cores (e.g., 4) |
spark_executor_instances | (none) | Number of Spark executor instances |
spark_config_name | {domain}.{table} or {transform_name} | Spark config identifier for per-task configuration |
Starlake environment options for Dataproc
These are set as Spark properties on the cluster:
| Option | Default | Description |
|---|---|---|
SL_HIVE | false | Enable Hive support |
SL_GROUPED | true | Enable grouped execution |
SL_AUDIT_SINK_TYPE | BigQuerySink | Audit sink type |
SL_SINK_REPLAY_TO_FILE | false | Replay to file (disabled for performance) |
SL_MERGE_OPTIMIZE_PARTITION_WRITE | true | Optimize partition writes |
SL_SPARK_SQL_SOURCES_PARTITION_OVERWRITE_MODE | dynamic | Partition overwrite mode |
dag:
template: "load/airflow_scheduled_table_dataproc.py.j2"
options:
dataproc_project_id: "my-project"
dataproc_region: "europe-west1"
dataproc_master_machine_type: "n1-standard-8"
dataproc_num_workers: "4"
spark_jar_list: "gs://my-bucket/jars/starlake.jar"
spark_bucket: "my-spark-bucket"
AWS Fargate
Executes starlake commands as ECS tasks on AWS Fargate.
Applies to: StarlakeAirflowFargateJob, StarlakeDagsterFargateJob
| Option | Default | Required | Description |
|---|---|---|---|
aws_conn_id | aws_default | No | Airflow connection ID for AWS |
aws_profile | default | No | AWS profile name |
aws_region | eu-west-3 | No | AWS region |
aws_cluster_name | (none) | Yes | ECS cluster name |
aws_task_definition_name | (none) | Yes | ECS task definition name |
aws_task_definition_container_name | (none) | Yes | Container name in the task definition |
aws_task_private_subnets | [] | Yes | JSON array of private subnet IDs |
aws_task_security_groups | [] | Yes | JSON array of security group IDs |
cpu | 1024 | No | CPU units for the container override |
memory | 2048 | No | Memory in MB for the container override |
AWS_SDK | /usr/local/aws-cli | No | Path to AWS SDK |
fargate_async_poke_interval | 30 | No | Polling interval in seconds for task completion |
retry_on_failure | false | No | Retry the Fargate task on failure |
dag:
template: "load/airflow_scheduled_table_fargate.py.j2"
options:
aws_cluster_name: "starlake-cluster"
aws_task_definition_name: "starlake-transform"
aws_task_definition_container_name: "starlake"
aws_task_private_subnets: '["subnet-abc123", "subnet-def456"]'
aws_task_security_groups: '["sg-abc123"]'
aws_region: "eu-west-1"
cpu: "2048"
memory: "4096"
Snowflake Tasks (SQL)
Executes starlake commands as native Snowflake stored procedures within Snowflake DAGs.
Applies to: StarlakeSnowflakeJob
| Option | Default | Required | Description |
|---|---|---|---|
stage_location | (none) | Yes | Snowflake stage location for stored procedure code (e.g., @my_stage/path) |
warehouse | (none) | No | Snowflake warehouse name |
packages | croniter,python-dateutil | No | Comma-separated list of Python packages available in stored procedures |
sl_incoming_file_stage | (none) | No | Snowflake stage for incoming files (required for load tasks) |
allow_overlapping_execution | false | No | Allow overlapping DAG executions for backfill support |
dag:
template: "transform/snowflake_scheduled_transform_sql.py.j2"
options:
stage_location: "@starlake_stage/code"
warehouse: "COMPUTE_WH"
packages: "croniter,python-dateutil,requests"
allow_overlapping_execution: "true"
Complete examples
Airflow + Bash (on-premise)
dag:
comment: "Load all tables using bash on Airflow"
template: "load/airflow_scheduled_table_bash.py.j2"
filename: "airflow_all_tables.py"
options:
sl_env_var: '{"SL_ROOT": "/opt/starlake", "SL_DATASETS": "/opt/starlake/datasets"}'
SL_STARLAKE_PATH: "/usr/local/bin/starlake"
pre_load_strategy: "imported"
retries: "2"
retry_delay: "60"
tags: "starlake load"
default_pool: "starlake_pool"
dag:
comment: "Run all transforms using bash on Airflow"
template: "transform/airflow_scheduled_task_bash.py.j2"
filename: "airflow_all_tasks.py"
options:
sl_env_var: '{"SL_ROOT": "/opt/starlake", "SL_DATASETS": "/opt/starlake/datasets"}'
SL_STARLAKE_PATH: "/usr/local/bin/starlake"
run_dependencies_first: "true"
retries: "2"
retry_delay: "60"
tags: "starlake transform"
Airflow + Cloud Run (GCP)
dag:
comment: "Load tables using Cloud Run on Airflow"
template: "load/airflow_scheduled_table_cloud_run.py.j2"
filename: "{{domain}}_cloud_run_load.py"
options:
sl_env_var: '{"SL_ROOT": "gs://my-bucket/starlake"}'
cloud_run_project_id: "my-project"
cloud_run_job_name: "starlake-load"
cloud_run_job_region: "europe-west1"
cloud_run_async: "true"
pre_load_strategy: "imported"
tags: "starlake cloud_run load"
Airflow + Dataproc (GCP)
dag:
comment: "Run transforms on Dataproc via Airflow"
template: "transform/airflow_scheduled_task_dataproc.py.j2"
filename: "{{domain}}_dataproc_tasks.py"
options:
dataproc_project_id: "my-project"
dataproc_region: "europe-west1"
dataproc_master_machine_type: "n1-standard-8"
dataproc_num_workers: "4"
spark_jar_list: "gs://my-bucket/jars/starlake.jar"
spark_bucket: "my-spark-bucket"
run_dependencies_first: "true"
tags: "starlake dataproc transform"
Airflow + Fargate (AWS)
dag:
comment: "Run transforms on Fargate via Airflow"
template: "transform/airflow_scheduled_task_fargate.py.j2"
filename: "{{domain}}_fargate_tasks.py"
options:
aws_cluster_name: "starlake-cluster"
aws_task_definition_name: "starlake-transform"
aws_task_definition_container_name: "starlake"
aws_task_private_subnets: '["subnet-abc123"]'
aws_task_security_groups: '["sg-abc123"]'
aws_region: "eu-west-1"
run_dependencies_first: "true"
tags: "starlake fargate transform"
Dagster + Shell (on-premise)
dag:
comment: "Load tables using shell on Dagster"
template: "load/dagster_scheduled_table_shell.py.j2"
filename: "dagster_all_load.py"
options:
sl_env_var: '{"SL_ROOT": "/opt/starlake"}'
SL_STARLAKE_PATH: "/usr/local/bin/starlake"
pre_load_strategy: "imported"
Dagster + Cloud Run (GCP)
dag:
comment: "Run transforms using Cloud Run on Dagster"
template: "transform/dagster_scheduled_task_cloud_run.py.j2"
filename: "dagster_all_tasks.py"
options:
sl_env_var: '{"SL_ROOT": "gs://my-bucket/starlake"}'
cloud_run_project_id: "my-project"
cloud_run_job_name: "starlake-transform"
cloud_run_job_region: "europe-west1"
run_dependencies_first: "true"
Snowflake Tasks
dag:
comment: "Run transforms as Snowflake Tasks"
template: "transform/snowflake_scheduled_transform_sql.py.j2"
filename: "snowflake_{{domain}}_tasks.py"
options:
sl_env_var: '{"SL_ROOT": ".", "SL_ENV": "SNOWFLAKE"}'
stage_location: "@starlake_stage/code"
warehouse: "COMPUTE_WH"
packages: "croniter,python-dateutil"
run_dependencies_first: "true"
allow_overlapping_execution: "true"
dag:
comment: "Load tables as Snowflake Tasks"
template: "load/snowflake_load_sql.py.j2"
filename: "snowflake_{{domain}}_{{table}}.py"
options:
sl_env_var: '{"SL_ROOT": ".", "SL_ENV": "SNOWFLAKE"}'
stage_location: "@starlake_stage/code"
warehouse: "COMPUTE_WH"
sl_incoming_file_stage: "@incoming_stage"